&color=rgb(100%2C100%2C100)&link=https%3A%2F%2Fgithub.com%2Faserto-dev%2Ftopaz)
Going beyond RBAC: a modern authorization panel
Jul 5th, 2023

Noa Shavit
ReBAC
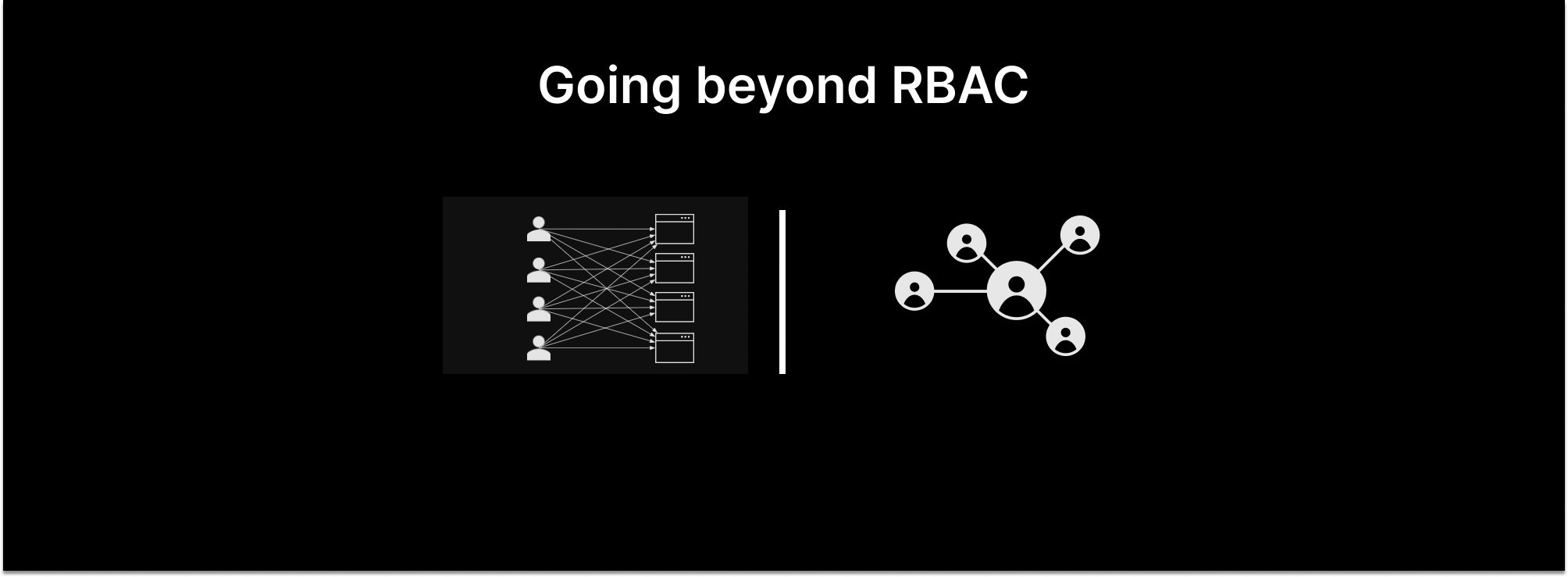
Every cloud-native app needs some form of access controls, yet most applications only offer role-based access controls (RBAC). A zero-trust approach requires that we go beyond RBAC to a fine-grained model. In these models authorization is defined on the application’s resources, often down to individual resources.
Two technical approaches have emerged for fine-grained access controls. We reviewed both approaches and discussed the strengths and weaknesses of each as foundational models for robust application access control systems with additional authorization vendors and end users with real world experience implementing centralized authorization systems for their organizations.
Tune into Aserto CTO (Gert Drapers), Bankdata Head of Authorization (Michael Lind Mortensen), Brainwave CTO (Sebastien Faivre), Omada CPTO (Benoit Grangé), SGNL CTO (Atul Tulshibagwale), and Styra Developer Advocate (Andres Eknert), as they discuss going beyond RBAC, or read about it below.
Introductions
Atul Tulshibagwale
I’m Atul, the CTO of SGNL, an authorization company. I’m also a co-chair of the OpenID Shared Signals working group, which standardizes the continuous access evaluation protocol (CAEP).
Benoit Grangé
I’m Benoit, CPTO for Omada, an identity security solution that is offering modern IGA solutions. Very pleased to be here. Technology is moving very rapidly, we need to adapt.
Sebastien Faivre
I'm Sebastien, CTO of Brainwave, a company that specializes in identity analytics. We’ve just been acquired by Radiant Logic. I'm very happy to be part of this panel, because authorization is the biggest challenge to overcome in the coming years.
Anders Eknert
Hello, I’m Anders, a developer advocate at Styra. I've been involved in the Open Policy Agent (OPA) project for the last four years.
Gert Drapers
I’m Gert, co-founder and CTO of Aserto. We're building an application authorization platform based on OPA, where we bring a data plane to OPA to make data management easier. We also provide a secure deployment chain for (OPA) policies though another open-source project called OPCR. Lastly, we’re bringing a relationship-based access control (ReBAC) model to OPA as the information endpoint in the environment (Topaz).
Michael Lind Mortensen
I'm Michael, head of authorization at Bankdata where we have implemented a centralized, policy-based access control solution in our very highly regulated industry. Glad to share my perspective on it.
What does it mean to go beyond RBAC?
Atul Tulshibagwale
A couple of things come to mind. First, we are continuously enforcing access. You aren't firing and forgetting. You're continuously, dynamically, adjusting the privileges as things change in the enterprise.
The second thing is the policies need to be scalable at enterprise level, so that they can be easily read and interpreted, and can be enforced at the same time.
Benoit Grangé
In my perspective, going beyond RBAC doesn't mean that we have to stop using RBAC. It’s a transition.
Moving to the cloud is something that is happening and we need to leverage it. We need to automate as much as possible. But to be successful, it will be very important to combine the new capabilities of cloud-native authorization, like policy-based access control, with the old ones, like RBAC. The key is to create a really efficient model.
Sebastien Faivre
I fully agree. It isn’t about opposing a legacy model (role-based access control) with a modern model, like policy-based access control. It's more about coarse-grained access control vs. fine-grained access controls. And the idea is to adopt an agile approach.
Anders Eknert
The approach we’ve taken in OPA is that RBAC is essentially a subset of attribute-based access control (ABAC). You're just working with a single attribute, which is the role. It seems silly to limit yourself to just that single attribute. There are so many other things that could be of importance.
Being agnostic about the data you manage also allows you to work with policy for a number of other interesting use cases, like infrastructure. Doing this allows you to answer questions like “Should user X be able to deploy cloud resource Y, given that it has an insecure configuration?”
What is the benefit of going beyond RBAC? What are the limitations that ABAC solves?
Anders Eknert
I think the most important thing is that ABAC opens the decision making process to others in the organization. Typically an admin sets the rules in an organization, but if you take any type of attribute into account, you democratize the process.
Gert Drapers
I think the biggest challenge with RBAC is not that it's bad, but it's restrictive. It's restrictive in what you can express and how fine-grained you can express it. Today we have a more expressive mechanism for access controls which allows for much finer-grained controls by combining relations and attributes.
But most importantly, I think the policy-based aspect is about the externalization of the authorization logic from the application. That's the big first step, the big move. Separating the concerns of the rule definition and how they're being used by the application. Only by separating them can they evolve independently.
Michael Lind Mortensen
There are clear benefits to ABAC over RBAC. Some of them have been touched upon already, maintenance being a big one. The beautiful thing about attributes, if you're modeling it correctly, is that it requires minimum maintenance, because it's a side effect of a business process.
Atul Tulshibagwale
With role-based access control, you tend to end up with a lot of permissions that you do not need. Sometimes representing the universe of everything that someone would need to do anytime in their job, which may not be what they should have access to.
As long as you can automate these processes, you can be very fine-grained with ABAC or ReBAC, and also be able to give real time audit trails, which simply is not possible today with role-based access controls.
How do we shift from static to dynamic access control?
Gert Drapers
RBAC is about sets. It’s nested groups and relations. You assign permissions to a role, and you use that to an actor or a group of actors. There's some inherent challenges with that model, like role explosion, but it doesn't necessarily make it bad.
I do believe that new approaches, like a relationship-based access control (ReBAC) model, which is based on relations between aspects, gives you more flexibility. Combining it with other models is even better. Sometimes you need to bring in attribute-based decision making.
I had a conversation with someone that told me they have 15,000 attributes and 300 more roles, because someone tried to encode location into a role. That doesn’t work together. We can do better and offer a more streamlined solution.
Sebastien Faivre
Just a small comment about moving from an RBAC model to a dynamic model. This transition means you’ll have to build fresh and sanitized data, because every decision will be based on data.
We want to make real time decisions based on attributes, based on policies. That means that all the automated decisions made by the policy engine will be based on data. So if you want to transition from a role-based model to a more dynamic attribute-based model, you need to think about clean and sanitized data. Do you have clean and sanitized data available in order to automate all the authorization decisions?
How do we help developers move beyond RBAC?
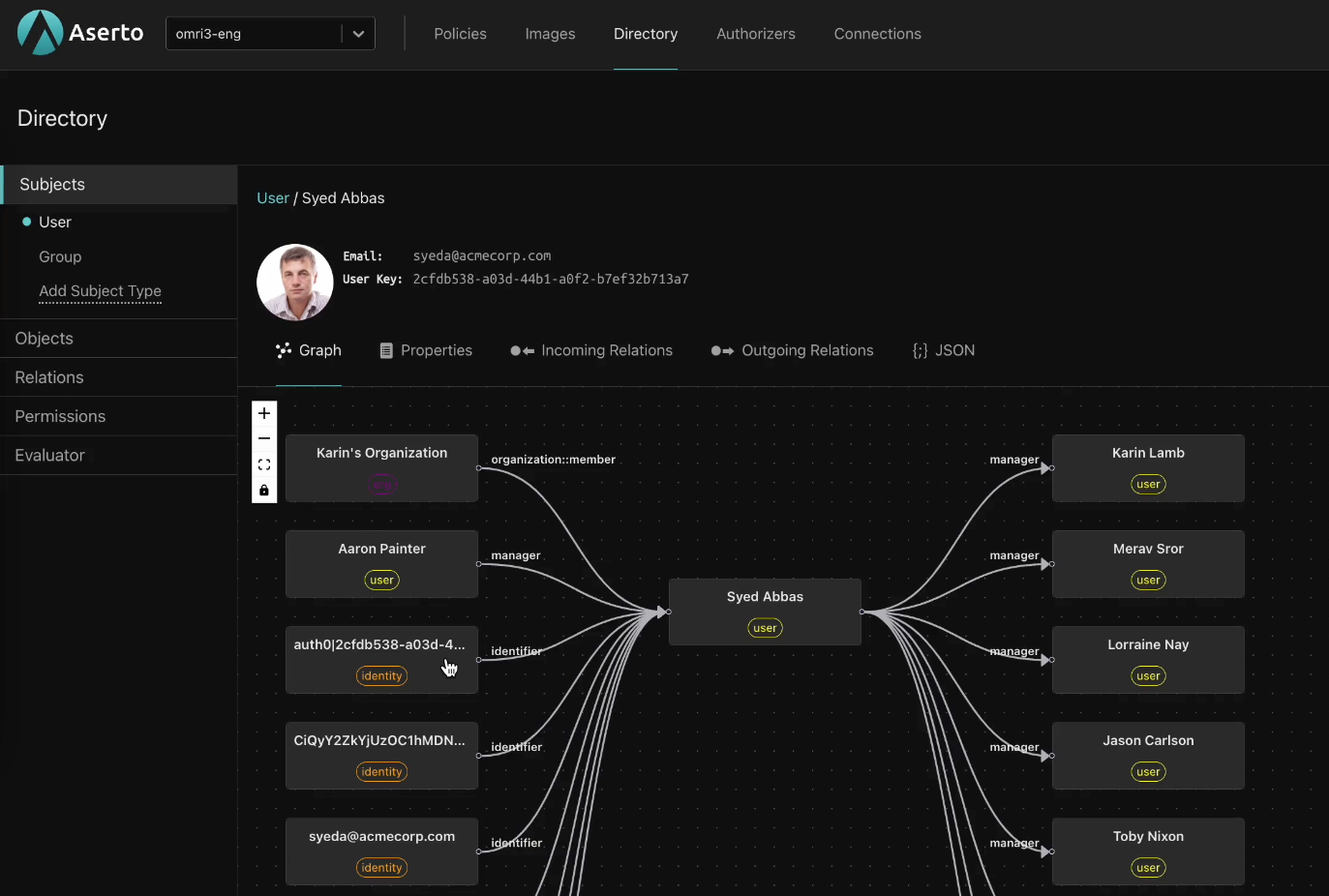
Gert Drapers
First, you need to have a common representation of the identities you deal with. Who is the actor? Is it a user? A machine? This is the most fundamental property, one you need in every decision. So it’s the first property set that you need to normalize around.
Once you have your identity information, modern applications should extract the authorization logic from application code, to enable separation of concerns. We can then manage policies separately from code, and develop a secure delivery pipeline to distribute them.
OPA has a perfect model in terms of distribution. We’ve added capabilities that mimic a Docker workflow. You can sign your policies, using Cosign, and store them in any artifact registry. When you consume that and combine it with signing, it is a secure untampered artifact that your authorizer can use to make decisions.
Atul Tulshibagwale
I think that a key aspect of policy management is that the policy that is interpreted in code needs to be readable by business people. And that is what gets certified as your official policy. Secondly, you need to have read reusability, so that the policies can be used regardless of the specific resource you're trying to protect with that policy. With that, you can multiply the use of that policy without having an explosion of the policies. Lastly, you need to have good access version control, and approvals so that you have good workflows that will allow business people to approve changes to policies, record those changes, and version them as needed.
Michael Lind Mortensen
I'm inclined not to fully agree that the policy needs to be readable by a business consultant, just because I don't think that's feasible. At least in the kind of context we would be in. Instead, what we have done is build verification suites. So if they've come up with a spec for us with the expected behavior based on business logic, we can test that against test cases and verify it works. But there's going to be a lot of details beyond that in the policy that the business people don't have to worry about. I generally would like to see more of a movement towards developers rather than towards business.
Atul Tulshibagwale
I just wanted to rebuttal that. It's not easy to make readable policies that are actually interpreted by code. I think one of the limitations of existing systems is that they go to a tuple based model, which resembles a row by row process. And as a result, the expressiveness of that model is very limited. But if you use a graph data model, which expresses the relationships in a very natural way, that graph is able to support the existence of these policies. While it may not be pure English, it is very close, and it can be interpreted by business people.
Anders Eknert
I feel the main point to make is that if there's only one change that you should be working on, that's to decouple policy. Do whatever you do after, but the most important aspect is that you actually decouple your authorization policy from code.
The identity folks, got this right. It’s how you do authentication - you send someone off to Auth0 or Okta, and they come back with a token to assert their identity. But, for some reason, when authorization or policy comes into play we are keen on doing that in our code.
Policy as code is not new. We've always been doing policy as code. It's just been embedded and coupled to our applications.
Do you have to move all of your applications at once?
Michael Lind Mortensen
No. I feel that a lot of times when people talk about implementing ABAC and policy-based access control, they think it needs to be applied everywhere. That it's universally a good idea. But sometimes it isn't. You have to take a risk-based approach.
Every time you add an OPA decision point as a sidecar, for example, that's a new thing that can break down. That's a new thing you can accidentally set limits incorrectly, or that has some other complexity in its configuration. So you need to be smart about how you're doing this. And you need to base it on inherent risk and the cost involved in doing it.
Conclusion
Every application needs some form of authorization to protect access to resources. RBAC is a popular access control pattern due to its simplicity. However it has drawbacks, like “role explosion,” and restrictions in terms of how fine-grained you can get.
The new approach to application authorization offers more flexibility and granularity. Fine-grained authorization models define access based on the application’s resources, often down to individual resources.
ABAC and ReBAC both have metrics, as does RBAC. Combining the three, and using them where they make most sense would be the ideal situation. Topaz is an open-source project that lets you do just that. Deploy it in your cloud today to start enjoying the benefits of fine-grained authorization for your applications.
Noa Shavit
Head of Marketing


Related Content

Open Policy Agent vs Google Zanzibar
There are two approaches to modern authorization. One extracts authorization logic from code and expresses it as a policy, and the other bases access on relationships between users/groups and application resources. In this post, we describe the pros and cons of each approach by reviewing representatives of each: OPA vs Zanzibar.
Nov 1st, 2023

Google vs Netflix’s approach to authorization: real-world examples of ReBAC and ABAC
Analyzing how popular applications provide fine-grained authorization is a good way to learn about the underlying access control methodologies. In this post, we compared the approaches that Google vs Netflix have taken to provide their users with fine-grained access control over the resources managed by these popular apps.
Nov 30th, 2023
How Airbnb and Uber authorize their apps: Real-world examples of ReBAC and ABAC
Explore real-world examples of attribute-based access control (ABAC) and relationship-based access control (ReBAC). Learn how Airbnb uses ReBAC to authorize external users and Uber uses ABAC to authorize internal users.
Feb 15th, 2024