&color=rgb(100%2C100%2C100)&link=https%3A%2F%2Fgithub.com%2Faserto-dev%2Ftopaz)
Open Policy Agent vs Google Zanzibar
Nov 1st, 2023

Noa Shavit
Open Policy Agent |
ReBAC

Cloud-native authorization is confusing for many reasons. It’s an emerging market. It involves complex technology. There are too many acronyms, policy languages, and modeling languages. And there are also many possible technical implementations, including OAuth scopes vs permissions that are checked in real-time, local library vs centralized service, hardcoded logic vs externalized authorization, etc.
Fundamentally, though, there are two approaches to cloud-native authorization. One uses code to define authorization policies and is known as the “policy-as-code” approach. The other approach bases access on the underlying application data, via a graph of relationships. This approach is known as “policy as data,” or graph-based authorization.
In this post, we compare the capabilities and shortcomings of each by looking at the representatives of both approaches, namely Open Policy Agent vs Google’s Zanzibar. But first, let's get a better idea of what the policy-as-code and graph-based approaches to authorization are.
Policy-as-code
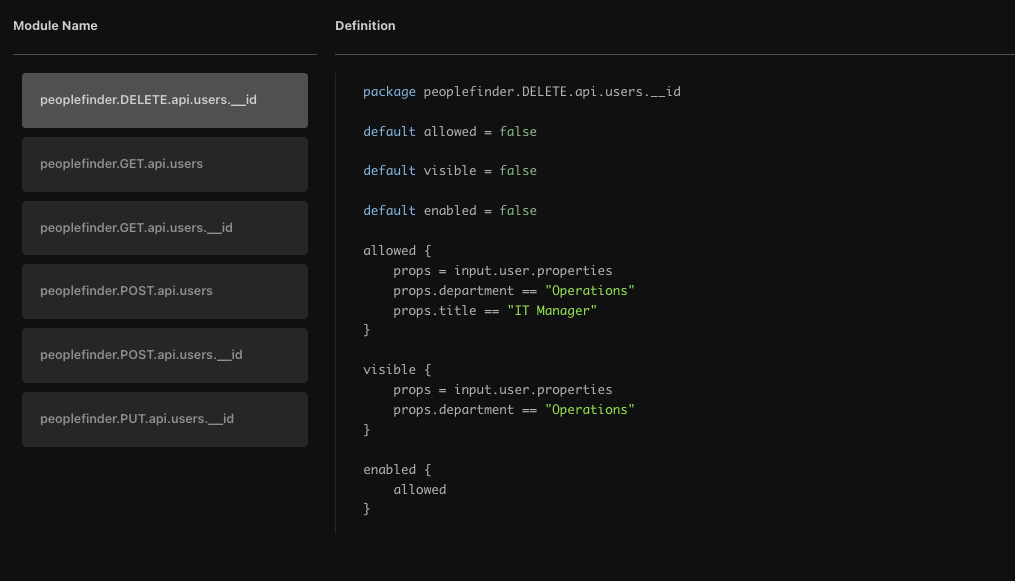
The policy-as-code approach to authorization starts with extracting authorization logic from application code and into an external policy. These policies are essentially lists of rules that determine which users have access to what resources. They are written in a domain specific language, like Rego or Cedar, and stored and versioned in their own repository, like any other application artifact.
The basic concept of this approach is decoupling authorization policy from application code. Once the authorization logic has been extracted from code and expressed as a policy, it is much easier to understand and maintain. This also allows for the reuse of policies, or parts of them, across applications and services for consistency and ease of governance.
Open Policy Agent (OPA) is perhaps the best known representative of this approach. It is a mature CNCF graduated project that has gained popularity for infrastructure authorization scenarios, like Kubernetes admission control. It uses Rego, a declarative language derived from Datalog, to define policies and provides a decision engine to enforce those policies.
Graph-based access controls
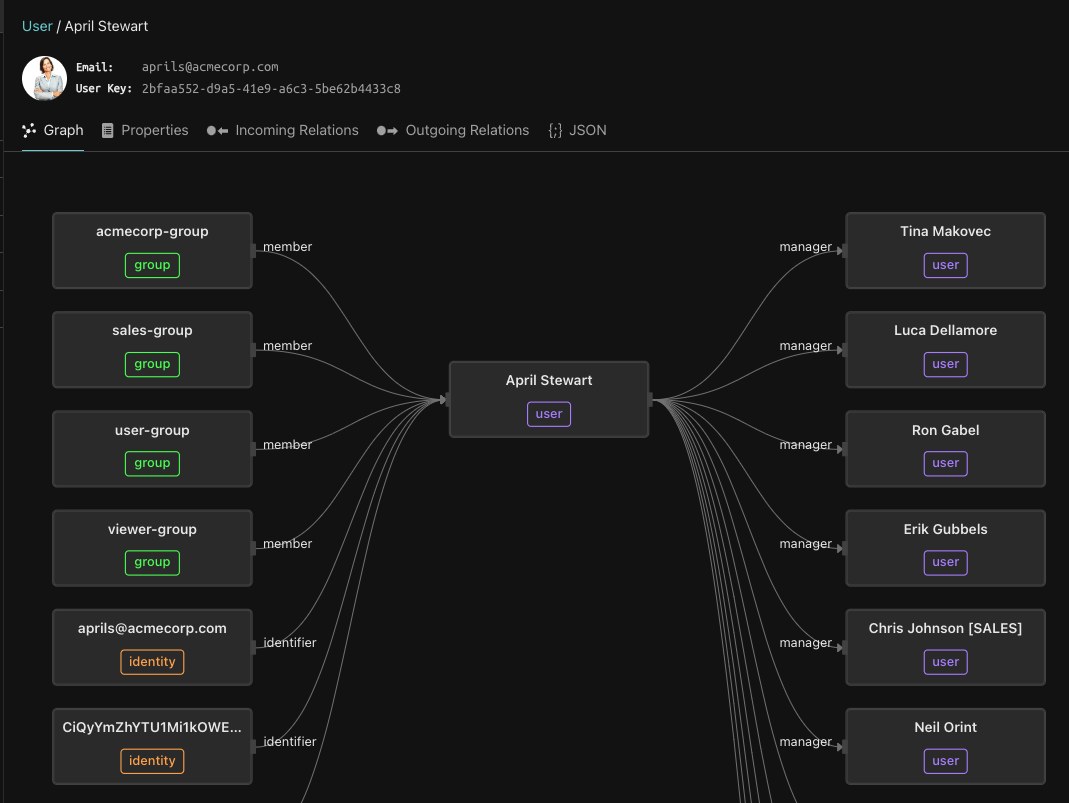
Rather than basing authorization on external policies, this approach bases it on the underlying data. Specifically, the relationships between subjects (users/groups) and objects (documents, folders, lists, projects, etc.) in the system are used to determine access. These tuples of subject/relationship/object are used to create a graph of relationships that is both easy to traverse and scale.
The first step in implementing graph-based authorization is to model your domain into object types, relationships, and permissions, and then provide the system with tuples that express instances of these relationships. Graph-based systems are extremely flexible, with support for custom objects and relation types. And given these are graphs, they come with built-in scalability, high-performance, and reverse indexes, as you can walk the graph in both directions.
Google’s Zanzibar paper has greatly popularized this approach to modern authorization. In this technical paper, the search giant describes its unified, graph-based authorization system, which is used for many of its external applications, including Docs, Calendar, Maps, and others. The paper has inspired many interpretations and implementations, such as SpiceDB, OpenFGA, and Topaz open-source authorizer.
Comparing policy & graph-based authorization: OPA vs Zanzibar
OPA’s policy as code
The policy-as-code approach provides absolute flexibility as you can express anything in code. It’s a natural fit for attribute-based access control (ABAC) systems, especially when environmental attributes (network, location, device, time, etc.) are fundamental.
Generally, policy-based authorization might be flexible enough to support complex policies, but it doesn’t have any native capabilities for describing hierarchies and inherited relationships. It also doesn’t support reverse lookup/indexes (e.g. “Who has access to this resource?” and not “Does that user have access to this resource?”). Policy-based access systems also tend to have a higher learning curve as developers need to master the policy language and build the mechanism to enforce it.
If we look at OPA specifically, we see a mature project. A single open-source implementation with a well-defined query API for evaluating authorization rules, a well-specified language for writing those rules, and extensibility points for vendors to add features.
With that said, OPA has no “opinions,” so you have to create your authorization model from first principles. And while OPA has a great policy plane, it doesn't have a data plane. So getting the data required to make authorization decisions to the decision engine is an exercise left for the implementing engineers. As a result, OPA tends to require a heavier initial investment than a graph-based authorization model, like Zanzibar.
Best fit for
- Applications with complex authorization policies
- Policies that use environmental attributes, like location, device, and network.
- Environments with low-medium levels of data/infrequent changes
Not suitable for
- Applications with authorization logic that uses inherently hierarchical permissions, parent-child relationships, containment, or other complex relationships.
- Systems that require reverse lookups/indexes (to answer the question “Who has access to this resource?” and not just the question “Can that user access this resource?”).
- Applications without dedicated resources to plan the system from first principles, and master Rego.
Zanzibar’s graph-based authorization
Graph-based authorization offers a flexible model allowing for resource-level authorization. But in contrast to the policy-as-code approach, these systems come with guardrails.
Graph-based authorization systems are built to scale, with a proven track-record of functioning well in high-volume situations. They also support complex relationships out-of-the-box, including those that are difficult to express in policy-as-code systems, namely inherited permissions, parent-child relationships, and reverse indexes.
Graph-based systems naturally support relationship-based access controls (ReBAC) and are flexible enough to support a surprising amount of use-cases. They are also more straightforward to set up and maintain, compared to policy-as-code systems like OPA. With that said, they can add administrative overhead for larger applications, as a reference to every resource that needs to be authorized must be present in both the application and relationship database.
As for Zanzibar itself, it’s important to note that the Zanzibar paper is just a set of ideas without an implementation. These ideas have inspired multiple interpretations and implementations. And each implementation has its own schema language to describe objects and their relationships, as well as its own set of APIs for adding relations and evaluating queries.
Indeed the Zanzibar-inspired ecosystem is a young one, that would greatly benefit from some commonality and re-usability across implementations that OPA, as a single open-source implementation, provides for the policy-as-code approach.
Best fit for
- High-volume systems
- Any data model that can be expressed as relationships between subjects and objects
- Applications with logic that uses complex relationships, like partner-child, inherited permissions, hierarchies like management relationships, etc. to determine access.
Not suitable for
- Applications that cannot describe authorization rules as relationships between subjects and objects. There aren’t many, but they do exist.
- Systems that rely on environmental attributes. There are easy workarounds for the attributes of the user and resource, but not for environmental attributes.
Topaz: Combining OPA with Zanzibar

Thankfully, you don’t have to limit yourself to just one approach. The Topaz open-source authorization system supports both approaches to cloud-native authorization. It provides built-in support for OPA policies, and the Zanzibar data-centric approach with an embedded relationship database. And it comes with everything you need to add popular authorization models to your applications (RBAC, ABAC, and ReBAC) in a matter of minutes.
We built Topaz because we believe that developers deserve to have the best of both worlds. And while Zanzibar and ReBAC answer a very wide range of use cases, being able to authorize on user, resource, and environmental attributes is critical for many scenarios as well.
Conclusion
There are two approaches to modern application authorization. One believes that access should be based on externalized policies and is best represented by OPA. The other brings access back to the underlying data, and has been popularized by Google’s Zanzibar paper.
We compared policy-as-code to graph-based authorization, by looking at OPA vs Zanzibar, and found that both have merits and shortcomings. OPA is great for managing complex policies, especially those using environmental attributes. However, it lacks built-in support for modeling relationships, like inherited permissions, as well as reverse indexes. Lastly, OPA tends to require more upfront investment, as it lacks a data plane, and the learning curve of Rego is steep
Zanzibar, on the other hand, was built to model complex relationships like hierarchical inheritance, parent-child relationships, containment, and others out-of-the-box. With that said, it is not suitable for use cases that rely on user, resource, or environmental attributes to determine access. It is also important to note that the Zanzibar-inspired ecosystem is younger than the policy-as-code ecosystem. So it might not be the best fit for very large enterprises that require a more mature ecosystem with more involved support.
Thankfully, you don’t have to choose. Topaz is an open-source authorization project that combines the best of each approach.
We’ve built Topaz for engineers, like yourself, so we would love to hear what you think! Drop us a line, or join our community Slack channel to share your thoughts. See you there!
Noa Shavit
Head of Marketing


Related Content

Gateway-enforced API Authorization
Learn how platform engineering teams can enforce service, method, and endpoint-level API access in a scalable way, without changing application code.
Jul 20th, 2024

API Authorization using Aserto and Zuplo
Platform Engineering teams that want to authorize access to their APIs now have a turnkey solution from Aserto and Zuplo.
Sep 25th, 2024

OPA : Zanzibar :: SOAP : REST?
As the saying goes, "those who do not learn history are doomed to repeat it." Is OPA vs Zanzibar shaping up to be the 2020's version of SOAP vs REST?
Apr 18th, 2023